ICLR 2026
DiVE-k: Differential Visual Reasoning for Fine-Grained Image Recognition
1University of Southern California
2Meta
We fine-tune LVLMs for fine-grained image recognition by turning the model's own top-k confusions into multiple-choice questions and training with RL — forcing differential reasoning among visually similar categories without brittle string-match rewards. DiVE-k outperforms prior methods by over 10% on the Harmonic Mean metric.
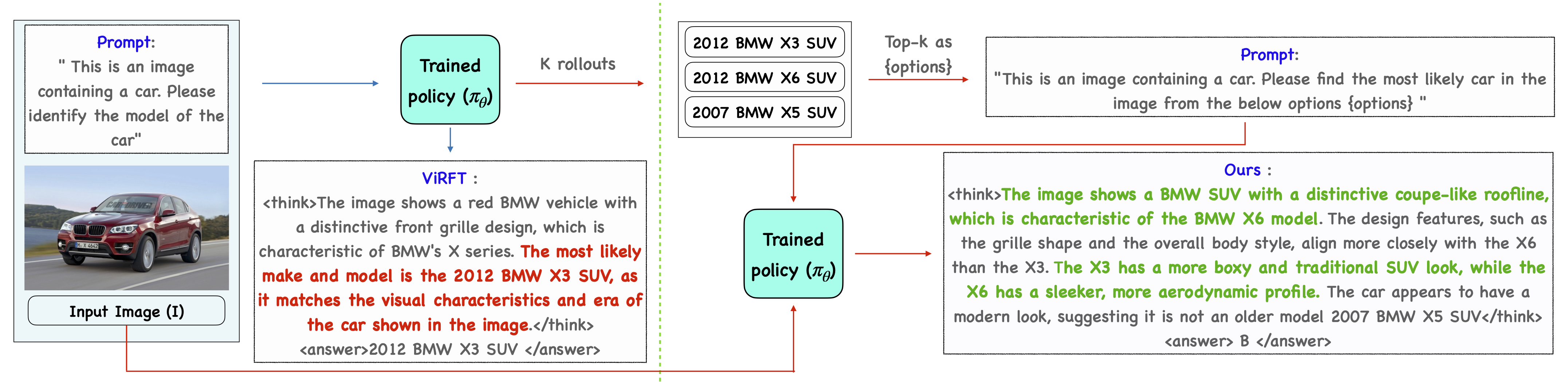
Large Vision Language Models (LVLMs) possess extensive text knowledge but struggle to utilize this knowledge for fine-grained image recognition, often failing to differentiate between visually similar categories. Existing fine-tuning methods using Reinforcement Learning (RL) with exact string-match reward are often brittle, encourage memorization of training categories, and fail to elicit differential reasoning needed for generalization to unseen classes.
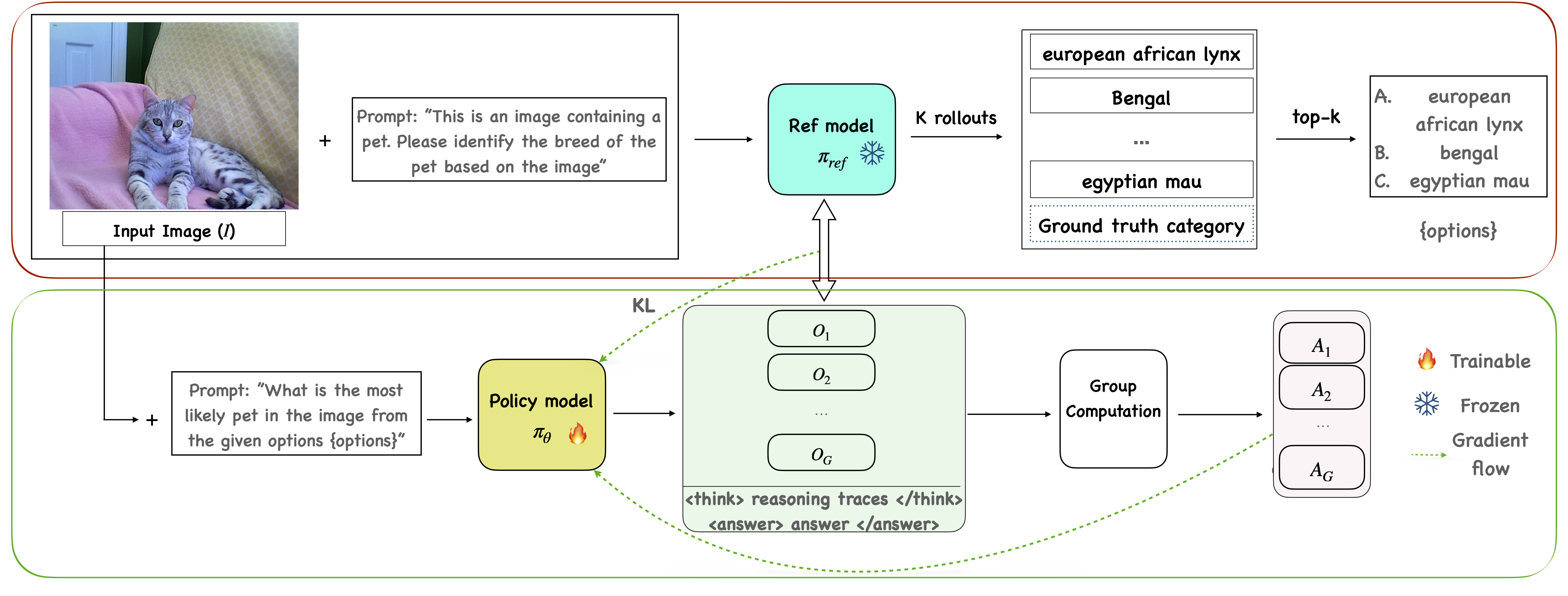
To address this, we propose DiVE-k (Differential Visual rEasoning using top-k generations), a framework that leverages the model's own top-k predictions as a training signal. For each training image, DiVE-k creates a multiple-choice question from the model's top-k outputs and uses RL to train the model to select the correct answer. This approach requires the model to perform fine-grained differential reasoning among plausible options and provides a simple, verifiable reward signal that mitigates memorization and improves generalization.
Experiments on five standard fine-grained datasets show that our method significantly outperforms existing approaches. In the standard base-to-novel generalization setting, DiVE-k surpasses QWEN2.5-VL-7B and ViRFT by 10.04% and 6.16% on the Harmonic Mean metric, respectively. Further experiments show similar gains in mixed-domain and few-shot scenarios.